SEARCH
ISTC-CC NEWSLETTER
RESEARCH HIGHLIGHTS
Ling Liu's SC13 paper "Large Graph Processing Without the Overhead" featured by HPCwire.
ISTC-CC provides a listing of useful benchmarks for cloud computing.
Another list highlighting Open Source Software Releases.
Second GraphLab workshop should be even bigger than the first! GraphLab is a new programming framework for graph-style data analytics.
ISTC-CC Research Overview
Cloud computing has become a source of enormous buzz and excitement, promising great reductions in the effort of establishing new applications and services, increases in the efficiency of operating them, and improvements in the ability to share data and services. Indeed, we believe that cloud computing has a bright future and envision a future in which nearly all storage and computing is done via cloud computing resources. But, realizing the promise of cloud computing will require an enormous amount of research and development across a broad array of topics.
ISTC-CC was established to address a critical part of the needed advancement: underlying cloud infrastructure technologies to serve as a robust, efficient foundation for cloud applications. The ISTC-CC research agenda is organized into four inter-related research "pillars" (themes) architected to create a strong foundation for cloud computing of the future:
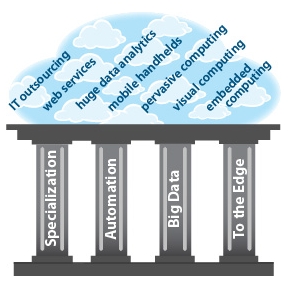 |
The four ISTC-CC pillars will provide a strong foundation for cloud computing of the future, delivering cloud's promised benefits to the broad collection of applications and services that will rely on it. |
Pillar 1: Specialization
Driving greater efficiency is a significant global challenge for cloud datacenters. Current approaches to cloud deployment, especially for increasingly popular private clouds, follow traditional data center practices of identifying a single server architecture and avoiding heterogeneity as much as possible. IT staff have long followed such practices to reduce administration complexity—homogeneity yields uniformity, simplifying many aspects of maintenance, such as load balancing, inventory, diagnosis, repair, and so on. Current best practice tries to find a configuration that is suitable for all potential uses of a given infrastructure.
Unfortunately, there is no single server configuration that is best, or close to best, for all applications. Some applications are computation-heavy, needing powerful CPUs and little I/O bandwidth, while others are I/O-bound and involve large amounts of random I/O requests. Some are memory-limited, while others process data in streams (from storage or over the network) with little need for RAM. And, some may have characteristics that can exploit particular hardware assists, such as GPUs, encryption accelerators, and so on. A multi-purpose cloud could easily see a mix of all of these varied application types, and a lowest-common-denominator type configuration will fall far short of best-case efficiency.
We believe that specialization is crucial to achieving the best efficiency—in computer systems, as in any large-scale system (including society), specialization is fundamental to efficiency. Future cloud computing infrastructures will benefit from this concept, purposefully including mixes of different platforms specialized for different classes of applications. Instead of using a single platform configuration to serve all applications, each application (and/or application phase, and/or application component) can be run on available servers that most closely match its particular characteristics. We believe that such an approach can provide order-of-magnitude efficiency gains, where appropriate specialization is applied, without yielding the economies of scale and elastic resource allocation promised by cloud computing.
Additional platforms under consideration include lightweight nodes (such as nodes that use Intel® Atom processors), heterogeneous many-core architectures, and CPUs with integrated graphics, with varied memory, interconnect and storage configurations/technologies. Realizing this vision will require a number of inter-related research activities:
- Understanding important application classes, the trade-offs between them, and formulating specializations to optimize performance.
- Exploring the impact of new technologies like non-volatile memory (NAND flash, phase change memory, etc.).
- Creating algorithms and frameworks for exploiting such specializations.
- Programming applications so that they are adaptable to different platform characteristics, to maximize the benefits of specialization within clouds regardless of the platforms they offer.
In addition, the heterogeneity inherent to this vision will also require new automation approaches.
Pillar 2: Automation
As computer complexity has grown and system costs have shrunk, operational costs have become a significant factor in the total cost of ownership. Moreover, cloud computing raises the stakes, making the challenges tougher while simultaneously promising benefits that can only be achieved if those challenges are met. Operational costs include human administration, downtime-induced losses, and energy usage. Administration expenses arise from the broad collection of management tasks, including planning and deployment, data protection, problem diagnosis and repair, performance tuning, software upgrades, and so on. Most of these become more difficult with cloud computing, as the scale increases, the workloads run on a given infrastructure become more varied and opaque, workloads mix more (inviting interference), and pre-knowledge of user demands becomes rare rather than expected. And, of course, our introduction of specialization (Pillar 1) aims to take advantage of platforms tailored to particular workloads.
Automation is the key to driving down operational costs. With effective automation, any given IT staff can manage much larger infrastructures. Automation can also reduce losses related to downtime, both by eliminating failures induced by human error (the largest source of failures) and by reducing diagnosis and recovery times, increasing availability. Automation can significantly improve energy efficiency, both by ensuring the right (specialized) platform is used for each application, by improving server utilization, and by actively powering down hardware when it is not needed.
Within this broad pillar, ISTC-CC research will tackle key automation challenges related to efficiency, productivity and robustness, with three primary focus areas:
- Resource scheduling and task placement: devising mechanisms and policies for maximizing several goals including energy efficiency, interference avoidance, and data availability and locality. Such scheduling must accommodate diverse mixes of workloads as well as specialized computing platforms.
- Devising automated tools for software upgrade management, runtime correctness checking, and programmer productivity that are sufficiently low overhead to be used with production code at scale.
- Problem diagnosis: exploring new techniques for diagnosing problems effectively given the anticipated scale and complexity increases coming with future cloud computing.
Pillar 3: Big Data
Data-intensive scalable computing (DISC) refers to a rapidly growing style of computing characterized by its reliance on large and often dynamically growing datasets ("BigData"). With massive amounts of data arising from such diverse sources as telescope imagery, medical records, online transaction records, checkout stands and web pages, many researchers and practitioners are discovering that statistical models extracted from data collections promise major advances in science, health care, business efficiencies, and information access. In fact, in domain after domain, statistical approaches are quickly bypassing expertise-based approaches in terms of efficacy and robustness.
The shift toward DISC and Big Data analytics pervades large-scale computer usage, from the sciences (e.g., genome sequencing) to business intelligence (e.g., workflow optimization) to data warehousing (e.g., recommendation systems) to medicine (e.g., diagnosis) to Internet services (e.g., social network analysis) and so on. Based on this shift, and their resource demands relative to more traditional activities, we expect DISC and Big Data activities to eventually dominate future cloud computing.
We envision future cloud computing infrastructures that efficiently and effectively support DISC analytics on Big Data. This requires programming and execution frameworks that provide efficiency to programmers (in terms of effort to construct and run analytics activities) and the infrastructure (in terms of resources required for given work). In addition to static data corpuses, some analytics will focus partially or entirely on live data feeds (e.g., video or social networks), involving the continuous ingest, integration, and exploitation of new observation data.
ISTC-CC research will devise new frameworks for supporting DISC analytics of Big Data in future cloud computing infrastructures. Three particular areas of focus will be:
- Understanding DISC applications, creating classifications and benchmarks to represent them, and providing support for programmers building them.
- Frameworks that more effectively accommodate the advanced machine learning algorithms and interactive processing that will characterize much of next generation DISC analytics.
- Cloud databases for huge, distributed data corpuses supporting efficient processing and adaptive use of indices. This focus includes supporting datasets that are continuously updated by live feeds, requiring efficient ingest, appropriate consistency models, and use of incremental results.
Note that these efforts each involve aspects of Automation, and that Big Data applications represent one or more classes for which Specialization is likely warranted. The aspects related to live data feeds, which often originate from client devices and social media applications, lead us into the next pillar.
Pillar 4: To the Edge
Future cloud computing will be a combination of public and private clouds, or hybrid clouds, but will also extend beyond large datacenters that power cloud computing to include billions of clients and edge devices. This includes networking components in select locations and mobile devices closely associated with their users that will be directly involved in many "cloud" activities. These devices will not only use remote cloud resources, as with today's offerings, but they will also contribute to them. Although they offer limited resources of their own, edge devices do serve as bridges to the physical world with sensors, actuators, and "context" that would not otherwise be available. Such physical-world resources and content will be among the most valuable in the cloud.
Effective cloud computing support for edge devices must actively consider location as a first-class and non-fungible property. Location becomes important in several ways. First, sensor data (e.g., video) should be understood in the context of the location (and time, etc.) at which it was captured; this is particularly relevant for applications that seek to pool sensor data from multiple edge devices at a common location. Second, many cloud applications used with edge devices will be interactive in nature, making connectivity and latency critical issues; devices do not always have good connectivity to wide-area networks and communication over long distances increases latency.
We envision future cloud computing infrastructures that adaptively and agilely distribute functionality among core cloud resources (i.e., backend data centers), edge-local cloud resources (e.g., servers in coffee shops, sports arenas, campus buildings, waiting rooms, hotel lobbies, etc.),and edge devices (e.g., mobile handhelds, tablets, netbooks, laptops, and wearables). This requires programming and execution frameworks that allow resource-intensive software components to run in any of these locations, based on location, connectivity, and resource availability. It also requires the ability to rapidly combine information captured at one or more edge devices with other such information and core resources (including data repositories) without losing critical location context.
ISTC-CC research will devise new frameworks for edge/cloud cooperation. Three focus areas will be:
- Enabling and effectively supporting applications whose execution spans client devices, edge-local cloud resources, and core cloud resources, as discussed above.
- Addressing edge connectivity issues by creating new ways to mitigate reliance on expensive and robust Internet uplinks for clients.
- Exploring edge architectures, such as resource-poor edge connection points vs. more capable edge-local servers, and platforms for supporting cloud-at-the edge applications.
Research Highlights
ISTC-CC provides a listing of useful benchmarks for cloud computing.
Another list highlighting Open Source Software Releases.
Ling Liu's SC13 paper "Large Graph Processing Without the Overhead" featured by HPCwire.
Second GraphLab workshop should be even bigger than the first! GraphLab is a new programming framework for graph-style data analytics.
Open-source Spark framework makes iterative and interactive data analytics FAST, both to run and to write.
Distributed system performance problems can be diagnosed by comparing traced request flows... [more]
Multiple frameworks (e.g., Hadoop and Dryad) can be run on the same cluster with Mesos... [more]
Open Cirrus offers free cloud computing resources, world-wide, based on open source systems... [more]
